Определяем вероятность исхода на основе коэффициентов
Знать, как оценить вероятность того или иного события на основе коэффициентов, крайне важно для выбора правильной ставки. Если вы не понимаете, как перевести букмекерский коэффициент в вероятность, то никогда не сможете определить, как соотносится букмекерский коэффициент с реальными шансами того, что событие состоится. Следует понимать, если вероятность события по версии букмекеров ниже, чем вероятность этого же события по вашей собственной версии, ставка на это событие будет ценной. Сравнить коэффициенты на разные события можно на сайте Odds.ru.1.1. Типы коэффициентов
Букмекерские конторы, как правило, предлагают три типа коэффициентов – десятичный, дробный и американский. Разберем каждую из разновидностей.
1.2. Десятичные коэффициенты
Десятичные коэффициенты при умножении на размер ставки позволяют рассчитать всю сумму, которую вы получите на руки в случае выигрыша.
Для того чтобы рассчитать вероятность события на основе десятичного коэффициента, необходимо провести простые вычисления – единицу разделить на коэффициент. Для вышеобозначенного коэффициента 1,80 расчет будет следующим:
1/1,80 = 0,55
То есть вероятность исхода, по версии букмекеров, составляет 55%.
1.3. Дробные коэффициенты
Дробные коэффициенты – наиболее традиционный вид коэффициентов. В числителе показана потенциальная сумма чистого выигрыша. В знаменателе – сумма ставки, которую нужно сделать, чтобы этот самый выигрыш получить. К примеру, коэффициент 7/2 означает, что для того, чтобы получить чистый выигрыш в размере 7 долларов, вам необходимо поставить 2 доллара.
Для того чтобы рассчитать вероятность события на основе десятичного коэффициента, следует провести простые вычисления – знаменатель разделить на сумму числителя и знаменателя. Для вышеобозначенного коэффициента 7/2 расчет будет таким:
Для вышеобозначенного коэффициента 7/2 расчет будет таким:
2 / (7+2) = 2 / 9 = 0,22
То есть вероятность исхода, по версии букмекеров, составляет 22%.
1.4. Американские коэффициенты
В первую очередь надо понимать, что американские коэффициенты бывают положительными и отрицательными. Отрицательный американский коэффициент всегда идет в формате, к примеру, «-150». Это означает, что для того, чтобы получить 100 долларов чистой прибыли (выигрыш), необходимо поставить 150 долларов.
Положительный американский коэффициент рассчитывается наоборот. К примеру, у нас есть коэффициент «+120». Это означает, что для того, чтобы получить 120 долларов чистой прибыли (выигрыш), вам необходимо поставить 100 долларов.
Это означает, что для того, чтобы получить 120 долларов чистой прибыли (выигрыш), вам необходимо поставить 100 долларов.
Теперь давайте рассмотрим, как же рассчитать вероятность исхода на основе положительных и отрицательных американских коэффициентов. Начнем с отрицательных.
Расчет вероятности на основе отрицательных американских коэффициентов делается по следующей формуле:
(-(отрицательный американский коэффициент)) / ((-(отрицательный американский коэффициент)) + 100)
или:
(-(-150)) / ((-(-150)) + 100) = 150 / (150 + 100) = 150 / 250 = 0,6
То есть вероятность события, на которое дается отрицательный американский коэффициент «-150», составляет 60%.
Теперь рассмотрим аналогичные вычисления для положительного американского коэффициента. Вероятность в этом случае рассчитывается по следующей формуле:
100 / (положительный американский коэффициент + 100)
или
100 / (120 + 100) = 100 / 220 = 0.45
То есть вероятность события, на которое дается положительный американский коэффициент «+120», составляет 45%.
1.5. Как переводить коэффициенты из одного формата в другой?
1.6. Как на основе вероятности рассчитать десятичный коэффициент?
Здесь все очень просто. Необходимо 100 разделить на вероятность события в процентном отношении. То есть, если предполагаемая вероятность события составляет 60%, вам надо:
100 / 60 = 1,66
При предполагаемой вероятности события в 60% десятичный коэффициент будет составлять 1,66.
1.7. Как на основе вероятности рассчитать дробный коэффициент?
В данном случае необходимо 100 разделить на вероятность события и от полученного результата отнять единицу.
(100 / 40) — 1 = 2,5 — 1 = 1,5
То есть мы получаем дробный коэффициент 1,5/1 или, для удобства счета, – 3/2.
1.8. Как на основе вероятного исхода рассчитать американский коэффициент?
Здесь многое будет зависеть от вероятности события – будет ли она более 50% или менее. Если вероятность события более 50%, то расчет будет производиться по такой формуле:
— ((вероятность) / (100 — вероятность)) * 100
Например, если вероятность события составляет 80%, то:
— (80 / (100 — 80)) * 100 = — (80 / 20) * 100 = -4 * 100 = (-400)
При предполагаемой вероятности события в 80% мы получили отрицательный американский коэффициент «-400».
Если вероятность события менее 50 процентов, то формула будет следующей:
((100 — вероятность) / вероятность) * 100
Например, если вероятность события составляет 40%, то:
((100-40) / 40) * 100 = (60 / 40) * 100 = 1,5 * 100 = 150
При предполагаемой вероятности события в 40% мы получили положительный американский коэффициент «+150».
Эти вычисления помогут вам лучше понять концепцию ставок и коэффициентов, научиться оценивать истинную стоимость той или иной ставки.
как правильно оценивать вероятность исходов в ставках?
Как определять исходы с завышенными коэффициентами, правильно оценивать вероятность спортивных событий и при чем здесь теория вероятности.
С опытом большинство игроков букмекерской конторы осознают, что ставки – это не только про спорт. Знания в спорте важны, они ключевые в беттинге, однако невозможно обыгрывать букмекера на дистанции, не разбираясь в математике, принципах формирования коэффициентов, статистике и теории вероятностей. Со временем игроки понимают, что мало делать точные прогнозы на матчи, важнее находить ставки с перевесом – так называемые валуи.
Как определять исходы с завышенными коэффициентами, правильно оценивать вероятность спортивных событий и при чем здесь теория вероятности
Её величество теория вероятности в ставках на спорт
Теория вероятности лежит в основе букмекерских ставок. По сути, всё построено вокруг вероятностей, как коэффициенты, так и шансы игрока на выигрыш. Без понимания этого момента ни за что не достичь успеха в беттинге. Абсолютно все игроки в меньшей или большей мере учитывают вероятность (шансы) при заключении пари, хотя большинство и не задумывается об этом.
Рассмотрим простой пример:
Для того чтоб объяснить теорию вероятности в ставках, обычно используется пример с подбрасыванием монеты. Не будем изобретать велосипед и разберемся с этим вопросом с помощью орла и решки, тем более что этот пример самый простой и понятный. Итак, вероятность выпадения орла – 50% и решки – 50%. Шансы равны.
Не будем изобретать велосипед и разберемся с этим вопросом с помощью орла и решки, тем более что этот пример самый простой и понятный. Итак, вероятность выпадения орла – 50% и решки – 50%. Шансы равны.
Если подбросить монету десять раз, может выпасть, к примеру, 7 орлов и 3 решки. Или даже десять раз подряд один и тот же вариант. Но если продолжать подбрасывать дальше, допустим, 100 000 раз, то получим значения близкие к 50% на 50%.
Переместим эту задачку в плоскость ставок. Сделать ставку на выпадения орла или решки можно с коэффициентом 2.00. Для того чтоб перевести шансы в коэффициенты, нужно 100 разделить на вероятность. Если сделать сто тысяч ставок на результат подбрасывания монеты, игрок в конечном итоге выйдет в ноль, или же прибыль/потери будут минимальными.
Распространенным является заблуждение игроков, которые полагают, что вероятность следующих событий зависит от результатов предыдущих. Если семь раз подряд выпала решка, какая вероятность выпадения решки в восьмой раз? Это противоречит интуитивному восприятию ситуацию, но шансы 50 на 50. При каждом новом броске, независимо от результатов предыдущих, вероятность каждого исхода будет 50%. Это явление называется ложный вывод Монте-Карло.
При каждом новом броске, независимо от результатов предыдущих, вероятность каждого исхода будет 50%. Это явление называется ложный вывод Монте-Карло.
Принципы формирования коэффициентов и образование валуев
Букмекеры определяют вероятность исходов и переводят её в коэффициенты, но перед тем как появится доступная для ставок роспись с различными вариантами, выполняется еще две операции:
- Закладывание маржи. Всем известно, что букмекерские конторы стабильно получают прибыль за счет дополнительного процента вероятности – маржа. В примере о решке и орле мы говорили, что коэффициенты на каждый исход должны быть 2.00. Но в реальности таких котировок нигде не найти, потому что после добавления маржи коэффициенты на равные шансы будут от 1.98 – 1.98 до 1.90 – 1.90 и ниже.
- Изменение коэффициентов в соответствие с ожидаемыми пропорциями ставок от игроков. В действительности для букмекеров более важно предугадать, на что будет ставить большинство, а не правильно оценить шансы.
 Если вероятность П1 в матче Челси – Бёрнли после учета маржи равна коэффициенту 1.70, то букмекерские конторы выставят где-то 1.62, поскольку знают, что большая часть денег будет поставлена именно на победу Челси. Соответственно, коэффициент на X и П2 увеличится после корректировки.
Если вероятность П1 в матче Челси – Бёрнли после учета маржи равна коэффициенту 1.70, то букмекерские конторы выставят где-то 1.62, поскольку знают, что большая часть денег будет поставлена именно на победу Челси. Соответственно, коэффициент на X и П2 увеличится после корректировки.
 Если вероятность П1 в матче Челси – Бёрнли после учета маржи равна коэффициенту 1.70, то букмекерские конторы выставят где-то 1.62, поскольку знают, что большая часть денег будет поставлена именно на победу Челси. Соответственно, коэффициент на X и П2 увеличится после корректировки.
Если вероятность П1 в матче Челси – Бёрнли после учета маржи равна коэффициенту 1.70, то букмекерские конторы выставят где-то 1.62, поскольку знают, что большая часть денег будет поставлена именно на победу Челси. Соответственно, коэффициент на X и П2 увеличится после корректировки.За счет маржи букмекеры имеют преимущество над игроками, о чем знают все. Если ставить на выпадение орла и решки по коэффициентам 1.98 – 1.98, то на длинной дистанции вы обязательно будете в минусе. Но есть возможность не только нивелировать это превосходство букмекерских контор, но и получить преимущество.
Для этого нужно ставить на валуи – ставки с перевесом, исходы с завышенными коэффициентами. Условный пример: ставки на орла принимаются с коэффициентом 1.90, а на решку – 2.02. Шансы были и остаются 50 на 50, но коэффициент 2.02 говорит о том, что вероятность равна 49.50% (100/2.02 = 49.50).
Разумеется, нужно ставить на решку за 2.02, что принесёт выгоду в долгосрочной перспективе, это валуй – ситуация, когда реальная вероятность наступления исхода выше, чем отражаемая коэффициентом вероятность.
Валуи редко встречаются в стартовой линии букмекерских контор, но благодаря движению линию – изменение коэффициентов после ставок игроков – шансы отыскать ставки с перевесом существенно увеличиваются.
Как вычислить вероятность события в ставках?
Если при игре в казино, например, рулетке, всегда известна вероятность того или иного результата, то в ставках на спорт никогда нельзя высчитать точную вероятность. И, собственно, по этой причине беттинг выгодно отличается от казино. Всегда можно найти ставки, вероятность которых выше установленной букмекером. Как же это сделать?
Не существует какого-то разработанного способа расчета вероятности, который мог бы максимально точно определять шансы. Это невозможно из-за влияния на результат множества факторов, непредсказуемости спорта в общем. Например, программы или формулы, куда можно было бы внести данные и получить приблизительный результат. Однако известен алгоритм действий для определения вероятности исходов. Рассмотрим его этапы.
Рассмотрим его этапы.
Первый этап – изучение статистики
Сама по себе статистика не позволяет получить даже приблизительную вероятность. Неправильно думать, что если в предыдущих 10 матчах команда 3 раза сыграла вничью, то вероятность ничейного исхода в следующем поединке составит 30%. Вспомним теорию вероятности, которая гласит, что предыдущие события не влияют на вероятность будущих. Но статистика служит отправной точкой, базой, ведь нужно же отчего-то отталкиваться.
Второй этап – влияние факторов
Определив с помощью статистики начальную вероятность, далее следует анализировать матч, учитывая как можно больше факторов. Следовательно, после изучения влияния каждого из них делаются поправки в вычисляемых вероятностях.
Именно на втором этапе всё зависит от того, насколько разбирается игрок в виде спорта, на который ставит. Как бы ни хотелось всё понятизировать и структурировать, невозможно точно рассчитать шансы и определить, как влияет на вероятность тот или иной фактор. Для каждого спортивного события нужен ситуативный подход.
Для каждого спортивного события нужен ситуативный подход.
Пример определения вероятности исходов в беттинге
Закрепим материал предыдущего пункта примером. Будем оценивать матч Арсенал – Ливерпуль, изучим основную линию. Коэффициенты следующие: победа Арсенала – 2.25, Ничья – 3.80, победа Ливерпуля – 3.05. Переведём котировки в вероятность. И получим следующее: П1 – 44.44%, X – 26.31%, П2 – 32.78%.
Теперь будем вычислять вероятность, после чего сравним с букмекерскими шансами и определим валуй, если таковой имеется. Сразу отметим, что все статистические данные и факторы условные.
Для начала изучаем статистику
Арсенал в последних 10 домашних матчах одержал 8 побед и 2 раза сыграл вничью. Получаем 80% – 20% – 0%. Ливерпуль в предыдущих 10 гостевых играх 6 раз выиграл, а также было 2 ничьи и 2 поражения. Имеем 20% – 20% – 60%. Высчитываем среднее значение: 50% – 20% – 30%.
После этого переходим ко второму этапу – учет различных факторов. Прежде всего, обращаем внимание на травмы и дисквалификации. У гостей практически без потерь, тогда как хозяева лишились из-за повреждений центрального защитника и левого инсайда. Корректируем вероятности после получения этой информации: 46% – 22% – 32%.
Прежде всего, обращаем внимание на травмы и дисквалификации. У гостей практически без потерь, тогда как хозяева лишились из-за повреждений центрального защитника и левого инсайда. Корректируем вероятности после получения этой информации: 46% – 22% – 32%.
Также в процессе предматчевого анализа мы узнаем, что Ливерпуль отдыхал на два дня больше, тогда как Арсенал свой предыдущий поединок провёл три дня назад. Может сказаться усталость. Изменяем шансы: 44% – 23% – 33%.
Смотрим на очные встречи команд
В последних пяти играх две победы Ливерпуля и три ничьи. Конечно же, шансы Арсенала заметно снижаются. Получим приблизительно: 40% – 25% – 35%. Других значимых факторов не выявили, поэтому заканчиваем анализ.
Итоговый результат 40% – 25% – 35%, а букмекерские вероятности П1 – 44.44%, X – 26.31%, П2 – 32.78%. Таким образом, валуйной является ставка на победу Ливерпуля – реальная вероятность 35%, а в коэффициент заложена 32. 78%.
78%.
Сложность в том, что не существует методов объективной оценки вероятности спортивных событий. Важнейшую роль в оценке вероятности играет субъективное мнение игрока, оценивающего матч. Но другого пути, кроме метода проб и ошибок, быть не может. Необходимо пробовать, использовать разные подходы, совершенствовать свою методику, что позволит с опытом максимально точно вычислять вероятности.
Иван Беленцов Профи
Опубликовано: 16.05.2018
Математики обыграли букмекеров
Wikimedia commons
Букмекеров можно обыграть, если учесть, что они иногда выставляют не самые выгодные для себя коэффициенты, чтобы снизить риски. Международная группа математиков проанализировала данные футбольных ставок за десять лет и разработала стратегию, с помощью которых выиграла у букмекеров тысячу долларов. После этого букмекеры ограничили им возможность делать ставки. Препринт работы опубликован на сайте arXiv.org.
Международная группа математиков проанализировала данные футбольных ставок за десять лет и разработала стратегию, с помощью которых выиграла у букмекеров тысячу долларов. После этого букмекеры ограничили им возможность делать ставки. Препринт работы опубликован на сайте arXiv.org.
За многие годы аналитики собрали огромное количество данных по футбольным матчам, что позволяет довольно точно предсказать их исход, учитывая разнообразные факторы. Например, при расчете вероятности команды выиграть матч учитываются результаты предыдущих встреч, количество забитых и пропущенных в прошлых играх голов, место проведения игры («дома» или «в гостях»), травмы игроков и даже погода, которую обещают синоптики. Исходя из предсказанных результатов, букмекеры рассчитывают оптимальные ставки и немного корректируют их, чтобы остаться в выигрыше.
Однако иногда букмекеры выставляют коэффициенты не такими выгодными для себя, как обычно. Это делается для того, чтобы привлечь больше клиентов, сбалансировать ставки и избежать слишком больших потерь. Например, если очень много людей ставит на выигрыш одной команды, букмекеры немного поднимают ставки на победу ее соперника. Благодаря этому часть людей предпочтет поставить не на «выигрышную» команду, и букмекеры несколько занижают вероятность выигрыша для клиентов букмекерской конторы по сравнению с фактической вероятностью победы команды. Именно этот факт использовали математики, чтобы их обыграть.
Например, если очень много людей ставит на выигрыш одной команды, букмекеры немного поднимают ставки на победу ее соперника. Благодаря этому часть людей предпочтет поставить не на «выигрышную» команду, и букмекеры несколько занижают вероятность выигрыша для клиентов букмекерской конторы по сравнению с фактической вероятностью победы команды. Именно этот факт использовали математики, чтобы их обыграть.
Для этого они проанализировали результаты и ставки на 479440 футбольных матчей, проведенных в 818 лигах за период с 2005 по 2015 год, и вывели формулу, которая позволяет рассчитать истинную вероятность выигрыша команды по вероятностям, объявленным букмекерами. Исходя уже из истинных значений вероятности они выбирали, на какую команду стоит поставить деньги. Потом они протестировали разработанную стратегию на исторической сводке закрывающих ставок (то есть ставок, которые объявляются прямо перед началом игры) за указанный период. Результаты работы алгоритма они сравнили с результатами модельного игрока, который делает ставки совершенно случайно. Во все случаях размер ставки оставался фиксированным и равным пятидесяти долларам.
Во все случаях размер ставки оставался фиксированным и равным пятидесяти долларам.
Оказалось, что разработанная математиками стратегия позволяет стабильно выигрывать и значительно превосходит стратегию случайных ставок. В то время как случайные игроки в среднем уходили в минус на девяносто тысяч долларов, игрок, знающий истинные вероятности, зарабатывал почти сто тысяч за тот же временной промежуток и для тех же доступных ставок. По словам авторов, только один из миллиона случайных игроков может добиться такого результата.
Сравнение заработанных на ставках денег для стратегии, разработанной математиками (синяя линия) и стратегии случайных ставок (красные линии). Данные для десятилетнего промежутка.
Lisandro Kaunitz et al
Сравнение заработанных на ставках денег для стратегии, разработанной математиками (синяя линия) и стратегии случайных ставок (красные линии). Данные для модельных игр, происходящих в режиме реального времени.
Данные для модельных игр, происходящих в режиме реального времени.
Lisandro Kaunitz et al
Это навело ученых на мысль проверить свою стратегию для реальных игр. Однако прежде чем делать настоящие ставки, они проверили ее на виртуальных играх, в которых они брали с букмекерских сайтов информацию о ставках и результатах матчей, а потом сравнивали, какую сумму можно было бы выиграть, придерживаясь этой стратегии. Стратегия работала все так же хорошо: за период с 1 сентября 2015 по 29 февраля 2016 ученые обработали данные по более чем тридцати тысячам игр и «выиграли» почти тридцать пять тысяч долларов, сделав около семи тысяч виртуальных ставок.
Затем математики применили разработанную стратегию к настоящим ставкам и заработали за пять месяцев чуть меньше тысячи долларов — и это при том, что авторы упустили много возможностей поставить деньги, поскольку делали это вручную. Спустя некоторый промежуток времени букмекеры начали ограничивать их возможность делать ставки, например, снижая доступную для ставки сумму. После этого математики посчитали невозможным продолжать эксперимент и прекратили играть. Авторы отмечают, что они не нарушали никаких правил, принятых в индустрии ставок.
Спустя некоторый промежуток времени букмекеры начали ограничивать их возможность делать ставки, например, снижая доступную для ставки сумму. После этого математики посчитали невозможным продолжать эксперимент и прекратили играть. Авторы отмечают, что они не нарушали никаких правил, принятых в индустрии ставок.
Выигрыш математиков в играх, происходящих в режиме реального времени. Синим показаны модельные ставки, красным — настоящие.
Lisandro Kaunitz et al
Примеры предупреждений букмекерских сайтов
Lisandro Kaunitz et al
Математики не первыми пытались обыграть букмекеров. Однако особенность разработанной ими стратегии заключается в том, что они не пытались построить лучшую предсказательную модель, как предыдущие «авантюристы», а считали, что букмекеры изначально обладают лучшими сведениями, просто не всегда выставляют наиболее выгодные для себя коэффициенты.
Однако особенность разработанной ими стратегии заключается в том, что они не пытались построить лучшую предсказательную модель, как предыдущие «авантюристы», а считали, что букмекеры изначально обладают лучшими сведениями, просто не всегда выставляют наиболее выгодные для себя коэффициенты.
Ранее мы писали о том, как математики рассчитали систему посева, при которой турниры получаются наиболее зрелищными.
Дмитрий Трунин
Odds: коэффициенты и вероятность выигрыша
https://www.facebook.com/paigereneespiranac/
Odds: коэффициенты и вероятность выигрыша
Odds как основа успешности. Как правильная оценка вероятностей влияет на итоговую доходность?
Читая англоязычные источники по ставкам, вы наверняка часто будете натыкаться на термин «odds». В общем-то это и не удивительно, поскольку именно он является основным центром внимания в текстах на беттинг тематику.
В общем-то это и не удивительно, поскольку именно он является основным центром внимания в текстах на беттинг тематику.
В переводе с английского odds означает вероятность, однако также этим термином зачастую принято обозначать букмекерские коэффициенты. В то же время, эти понятия все-таки следует разделять. Рассмотрим классический пример: двухисходное событие с одинаковыми вероятностями исхода. Шансы на победу каждой из сторон равные – 50 / 50. Соответственно, коэффициент на них должен даваться 2.0 и 2.0. Тем не менее, как вы уже знаете из предыдущих статей, букмекер закладывает собственную маржу во всех исходы, из-за чего коэффициентное отображение несколько искажается, и мы получаем, например, не 2.0 и 2.0, а 1.95 и 1.95. Иными словами при равной вероятности наступления одного из событий, коэффициенты на него несколько занижены.
Как повысить шансы на проход вашего прогноза?
Данный вопрос является ключевым, поскольку он напрямую связан с доходностью ваших ставок. Рассмотрим несколько факторов влияющих на улучшение показателей по проходам:
Рассмотрим несколько факторов влияющих на улучшение показателей по проходам:
- Odds scanner. Крайне важная штука, зачастую бесплатная к тому же. Многие начинающие бетторы пренебрегают анализом коэффициентов и ставят где придется. А зря! Минимальная разница в коэффициентах на дистанции может сильно изменить картину успеха.
- Анализ шансов. Odds-чекинг – это, с одной стороны, довольно просто, а с другой – не очень. Теоретически вы сопоставляете линию вероятностей букмекера, с вашим ожиданием и, если считаете, что букмекер дал некорректную линию, грузите на валуй и дело в шляпе. Звучит легко, но на практике таких уникумов меньше 10%.
- Психологическая подготовка. Адекватная оценка фактов, информации и собственных возможностей важна не меньше, чем доскональное понимание математики букмекерства. Особенно, когда вы находитесь под гнетом даунстрика.
- Самоанализ. Осознание собственные ошибок – это уже огромное преимущество. Их искоренение и работа над собой по всем аспектам – залог успеха.
Резюме
Итак, чтобы правильно оценивать вероятности (они же odds) важно понимать всю цепочку формирования коэффициентов. Когда каппер ловко орудует вероятностью, конвертируемой в коэффициенты, он легко может находить валуйные ставки. Помните, что сама по себе вероятность без учета маржи, хороша лишь в теории. На практике вы должны научиться выжимать максимальное велью из представленных коэффициентов и неверных котировок букмекера.
Добавьте #PPS в список ваших источниковСемьянин на миллион. Как британский топ-беттор совмещает ставки на спорт и многодетную семью
Теннис – самый договорной вид спорта. Увы, но это так
 000Z» data-v-2a6ced78=»»>2021-01-31T19:00:55.000Z
000Z» data-v-2a6ced78=»»>2021-01-31T19:00:55.000ZПередел рынка или пустышка? БК PokerStars нацелилась на Россию
Много голов в игре «Авангарда» и «Локомотива», победа минского «Динамо» над «Витязем». Ставки на игры КХЛ
4 шага, как распознать ставки с завышенными коэффициентами — Академия ставок — Блоги
Что такое ставки с завышенным коэффициентом?
Стратегия ставок по завышенным коэффициентом – это умение определять преимущество над букмекером по коэффициентам, в которых заложена вероятность ниже, чем та, которую определил своими расчётами игрок.
Игра на завышенных коэффициентах строится на способности определять преимущество над линией выставленной букмекером. Для этого игроку нужно уметь самостоятельно рассчитывать вероятность того или иного исхода в предстоящем событии. И, если у него это получается делать лучше, чем у букмекера, то можно ожидать прибыль на длительной дистанции. Проще говоря, если вероятность, выраженная в предлагаемом коэффициенте ниже, чем определил игрок, то такая ставка несёт в себе ценность.
И, если у него это получается делать лучше, чем у букмекера, то можно ожидать прибыль на длительной дистанции. Проще говоря, если вероятность, выраженная в предлагаемом коэффициенте ниже, чем определил игрок, то такая ставка несёт в себе ценность.
Ценность — обычный термин, используемый в инвестировании, но и в ставках на спорт имеет такое же значение. Это подразумевает, что найденные Вами компании с недооценёнными активами принесут прибыль, так как их акции в дальнейшем могут вырасти в цене.
Успешные игроки понимают разницу между вероятностью того, что событие произойдёт и тем, как это отображается на выставленных букмекером коэффициентах. Для получения стабильной прибыли Вам стоит безоговорочно следовать стратегии ставок по завышенным коэффициентам, как только Вы их обнаружили, не зависимо от того, какова вероятность, что это произойдёт и ставить деньги обязательно по имеющемуся у Вас банкроллу. Конечно, придерживаться такого подхода очень непросто, чем следовать за фаворитом, победа которого всегда более вероятна. Но такая стратегия при столь не высоких коэффициентах не несёт в себе никакой ценности. В отличии от этого, надёжными инструментами для успеха в ставках на долгосрочной дистанции является понимание вероятности конкретного исхода и определение тех рынков, которые уязвимы к использованию стратегии завышенных коэффициентов.
Но такая стратегия при столь не высоких коэффициентах не несёт в себе никакой ценности. В отличии от этого, надёжными инструментами для успеха в ставках на долгосрочной дистанции является понимание вероятности конкретного исхода и определение тех рынков, которые уязвимы к использованию стратегии завышенных коэффициентов.
Игра на ставках построена на том, что каждому событию заложена вероятность в диапазоне от 0% (невозможно) до 100% (определенно). А потом уже сотрудники букмекерских компаний определяют эту вероятность и переводят в коэффициенты.
- Стратегия игры по завышенным коэффициентам оправдывает себя лишь в том случае, когда доступные коэффициенты не являются истинным отражением вероятности возникновения предстоящего исхода.
Разногласия с букмекером
Если Вы часто находите ставки с завышенными коэффициентами, то на длительной дистанции станете успешным игроком. Однако, букмекерские конторы никогда умышленно не создают благоприятные возможности, так как коэффициенты, которые они предлагают не представляют истинной вероятности события. В порядке создания росписи, букмекеры обеспечивают себе преимущество тем, что закладывают маржу и воздействуют на коэффициенты, чтобы сбалансировать свои рынки. Если настоящий букмекер предложил бы Вам коэффициенты на подкидывание монетки, то они, вероятно были бы по 1.90 на орла и решку с маржой в 5%, при том, что истинный коэффициент ровняется 2. Простые подсчёты покажут, что каждый раз ставя по $10 на дистанции Ваш банкролл скорее всего будет уменьшатся, из чего следует, что такая ставка очень невыгодная.
В порядке создания росписи, букмекеры обеспечивают себе преимущество тем, что закладывают маржу и воздействуют на коэффициенты, чтобы сбалансировать свои рынки. Если настоящий букмекер предложил бы Вам коэффициенты на подкидывание монетки, то они, вероятно были бы по 1.90 на орла и решку с маржой в 5%, при том, что истинный коэффициент ровняется 2. Простые подсчёты покажут, что каждый раз ставя по $10 на дистанции Ваш банкролл скорее всего будет уменьшатся, из чего следует, что такая ставка очень невыгодная.
Поэтому возникает логичный вопрос: если букмекер поступает не справедливо, то как игроки могут получать прибыль? Да, спору нет, сотрудники контор мастера по выставлению точных коэффициентов для создания маржи, которая позволяет им получать прибыль. Но спорт не столь подвластен количественному определению, как рулетка или подбрасывание монетки. В матчах есть очень много переменных, которые могут повлиять на результат и именно на этом Вы сможете получить преимущество при помощи игры по стратегии завышенных коэффициентов.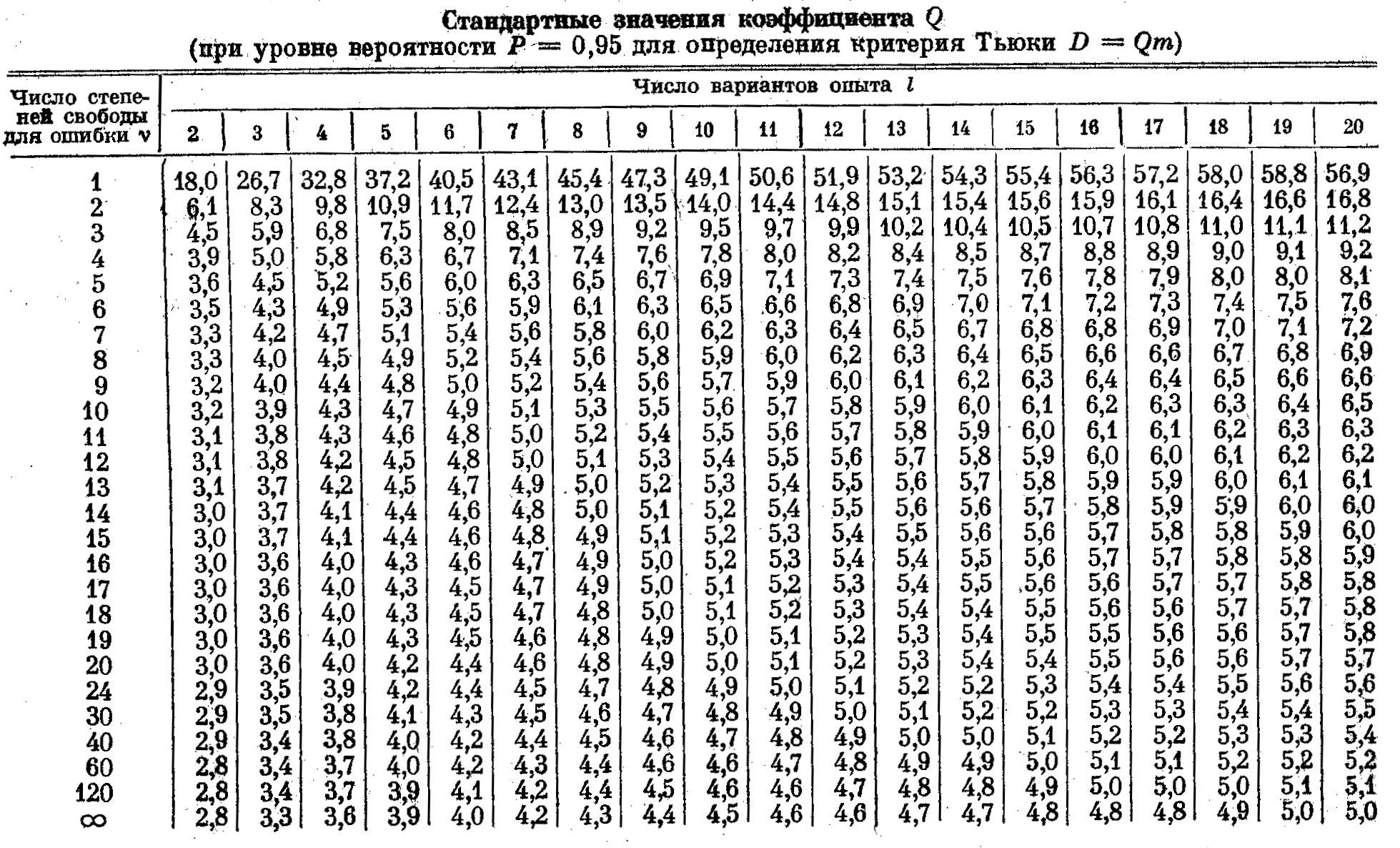
Как распознавать ставки с завышенными коэффициентами?
Обрести навык определения ставок с завышенным коэффициентом очень сложная задача. Давайте разберёмся что Вам для этого нужно.
1. Выставляйте свои собственные коэффициенты
Как и финансовые аналитики, успешные игроки должны рассчитывать свои собственные коэффициенты по профильным рынкам, используя всю имеющуюся по ним информацию. При определении своей собственной вероятности Вы сможете сравнить её с той, которую заложил букмекер и таким образом отметить будет ли такая ставка выгодной или нет. Аналитики Enlight Sport Analytics успешно пользуются этой стратегией, что позволяет нам показывать успешный результат на длительной дистанции.
2. Думайте о вероятностях, а не о фаворитах и андердогах
Цель стратегии игры по завышенным коэффициентам, как мы знаем это точнее оценить вероятность события, чем букмекер или другие игроки на Вашем профильном рынке. Так будет у Вас получатся, если мыслить в плоскости допустимости, а не только величиной фаворита при оценке его шансов на победу, основываясь на том, что Вы просто так считаете или в это верите.
Фавориты не выигрывают все время. Вместо этого, как только вы рассчитали свои собственные шансы, Вы должны стремиться выявлять различия в предполагаемых вероятностях для каждого результата по сравнению с тем, что предлагается. Если это так, вы нашли значение ставки, считая, что вы можете более точно рассчитать истинные вероятности. Не беспокойтесь, если ставите по стратегии завышенных коэффициентов на андердога или на событие, которое по Вашему субъективному мнение маловероятно, просто следуйте выбранной стратегии.
3. Анализ и оценка
Математический подход более контролируемый и рациональный в сравнении с хорошим чутьём, так как он откидывает эмоциональную составляющую в принятии решений в ставках на спорт. Как бы то ни было, делая расчёты, Вы должны проанализировать и оценить всю имеющуюся информацию, потому что ряд факторов, которые Ваш подход не включал могут серьёзно повлиять на получение прибыли на долгой дистанции. Учитывая это, Вы сможете принять выверенное и сбалансированное решение. Команда Enlight Sport Analytics имеет огромный опыт в сфере ставок на спорт, который помог нам сформировать свою успешную стратегию с использованием завышенных коэффициентов.
Команда Enlight Sport Analytics имеет огромный опыт в сфере ставок на спорт, который помог нам сформировать свою успешную стратегию с использованием завышенных коэффициентов.
4. Специализация
Лучший путь для получения прибыли — это специализироваться на тех рынках, которые позволят Вам, как игроку быть в более равных условиях с букмекером. Если Вы будете иметь хорошее понимание в определённой нише, то сможете идентифицировать не совсем точную расстановку вероятностей, получив тем самым возможность сделать ставки по завышенным коэффициентам.
Применение в ставках на спорт
Если Вы хотите получить прибыль на долгосрочной дистанции, то всегда используйте в своей игре стратегию завышенных коэффициентов, так как они всего лишь выражение вероятностей. Старайтесь определять истинные шансы для того или иного исхода точнее, чем это делает букмекерская контора и это увеличит Ваши возможности получать прибыль. Для того чтобы стать успешным игроком, Вам стоит разрабатывать свои собственные методы расчётов, создавать собственные коэффициенты для ставок на спорт.
Автор: Enlight Sport Analytics
Блог: Enlight Sport Analytics
Читайте самые горячие 🔥 материалы «Академии»:
Как проверить надежность стратегии ставок
15 критериев анализа матча для ставки
7 шагов для отбора матча для игры на тотал больше
как понять, что это такое значит?
Что такое вероятность в ставках?
Чем характеризуется вероятность в букмекерских конторах?
Как преобразовать разные виды коэффициентов в вероятность?
Вероятность – это оценка степени прохода той или иной ставки.
Вероятность выигрыша ставки в букмекерских конторах характеризуется коэффициентами. Зависимость коэффициента и вероятности обратно пропорциональная. Другими словами, чем ниже вероятность прохода события, тем выше коэффициент.
Вероятность измеряется в процентах. Рассмотрим способы перевода разных видов коэффициентов в проценты на конкретных примерах. Существует несколько видов коэффициентов: европейский (десятичный), британский (дробный) и американский.
Существует несколько видов коэффициентов: европейский (десятичный), британский (дробный) и американский.
Европейский коэффициент выглядит как десятичная дробь. Например, коэффициент на победу Кьево над Торино составляет 3,16. Вероятность рассчитывается по формуле: 1/коэффициентХ100%. В нашем случае вероятность победы Кьево над Торино составляет 1/3,16Х100%=31%.
Британский коэффициент выглядит как дробь. Например, коэффициент на победу Ливерпуля над Уимблдоном составляет 1/4. Вероятность рассчитывается по формуле: (Знаменатель / (Числитель + Знаменатель)) Х100%. В нашем случае вероятность победы Ливерпуля над Уимблдоном составляет (4/(4+1))Х100%=80%.
Американский коэффициент бывает двух видов – положительный и отрицательный. Положительный коэффициент показывает, какую чистую прибыль вы можете получить, поставив 100 единиц, а отрицательный – какой суммой необходимо пожертвовать, чтобы выиграть 100 единиц. Например, коэффициент на победу Лацио над Сампдорией составляет -139, а коэффициент на победу Сампдории над Лацио составляет +430. Вероятность для первого варианта рассчитывается по формуле: 100% Х ( — (Коэф.)) / (( — (Коэф.)) + 100). В нашем случае вероятность будет 100%Х(-(-139))/((-(-139))+100)=58%. Вероятность для второго варианта рассчитывается по формуле: 100%Х100 / (Коэф. + 100). В нашем случае вероятность будет 100%Х100/(430+100) = 19%
Вероятность для первого варианта рассчитывается по формуле: 100% Х ( — (Коэф.)) / (( — (Коэф.)) + 100). В нашем случае вероятность будет 100%Х(-(-139))/((-(-139))+100)=58%. Вероятность для второго варианта рассчитывается по формуле: 100%Х100 / (Коэф. + 100). В нашем случае вероятность будет 100%Х100/(430+100) = 19%
Прогнозирование банкротства — Контур.Эксперт — СКБ Контур
Банкротство — широко распространенная проблема, с которой сталкиваются в процессе деятельности индивидуальные предприниматели и юридические лица. Множество организаций ежегодно подвергаются банкротству в нашей стране; поэтому своевременное выявление неблагоприятных тенденций имеет первостепенное значение.
Что такое банкротство?
Банкротство — это неспособность организации платить по своим долговым обязательствам и финансировать текущую основную деятельность из-за отсутствия денежных средств. Основным признаком банкротства является просрочка в уплате долга более чем на 3 месяца.
Вероятность банкротства — это одна из оценочных характеристик текущего финансового состояния в исследуемой организации. Руководство предприятия может постоянно поддерживать вероятность на низком уровне, если будет периодически проводить анализ вероятности банкротства, и вовремя принимать необходимые меры.
Z-счет Альтмана
В настоящее время существуют различные методики оценки вероятности банкротства предприятия. Наиболее точными в условиях рыночной экономики являются многофакторные модели прогнозирования банкротства, которые обычно состоят из пяти-семи финансовых показателей. В практике для оценки вероятности банкротства наиболее часто используется так называемый «Z-счёт» Альтмана. Итоговый коэффициент вероятности банкротства Z представляет собой функцию от пяти показателей, характеризующих экономический потенциал предприятия и результаты его работы за истекший период: структуру активов и пассивов, рентабельность и оборачиваемость. Каждый из показателей был наделён определённым весом, установленным статистическими методами.
Каждый из показателей был наделён определённым весом, установленным статистическими методами.
Z = 1,2 * K1 + 1,4 * K2 + 3,3 * K3 + 0,6 * K4 + K5, где
K1 — доля оборотных активов в суммарных активах организации. Показатель характеризует степень ликвидности организации.
K2 — рентабельность активов по нераспределенной прибыли. Показатель характеризует уровень финансового рычага организации.
K3 — рентабельность активов по прибыли до уплаты налогов. Показатель характеризует эффективность операционной деятельности организации.
K4 — соотношение собственного и заемного капиталов.
K5 — оборачиваемость активов. Показатель характеризует рентабельность активов предприятия.
В зависимости от значения «Z-счёта» по определённой шкале производится оценка вероятности наступления банкротства в течение двух лет. При анализе организации следует обращать внимание не столько на шкалу вероятностей банкротства, сколько на динамику этого показателя.
Z-счет Альтмана позволяет определить не только риск банкротства, но и уровень кредитоспособности, поэтому применяется банками для оценки кредитоспособности заемщика, финансовой устойчивости и вероятности банкротства.
Как найти коэффициент вариации
Как найти коэффициент вариации: содержание :
- Что такое коэффициент вариации?
- Как найти коэффициент вариации
Коэффициент вариации (CV) является мерой относительной изменчивости. Это отношение стандартного отклонения к среднему (среднему). Например, выражение «Стандартное отклонение составляет 15% от среднего» — это CV.
CV особенно полезно, когда вы хотите сравнить результаты двух разных опросов или тестов, которые имеют разные меры или значения.Например, если вы сравниваете результаты двух тестов с разными механизмами оценки. Если для образца A CV составляет 12%, а для образца B — 25%, можно сказать, что образец B имеет больше вариаций по сравнению со своим средним значением.
Формула
Формула для коэффициента вариации :
Коэффициент вариации = (Стандартное отклонение / Среднее) * 100.
В символах: CV = (SD /) * 100.
Умножение коэффициента на 100 — это необязательный шаг для получения процента, а не десятичного числа.
Пример коэффициента вариации
Исследователь сравнивает два теста с множественным выбором с разными условиями. В первом тесте проводится типичный тест с множественным выбором. Во втором тесте альтернативные варианты (то есть неправильные ответы) случайным образом назначаются испытуемым. Результаты двух тестов:
| Обычный тест | Случайные ответы | |
| Среднее значение | 59,9 | 44,8 |
| SD | 10.2 | 12,7 |
Попытка сравнить результаты двух тестов является сложной задачей. Сравнение стандартных отклонений не работает, потому что означает, что тоже разные. Расчет по формуле CV = (SD / Среднее) * 100 помогает разобраться в данных:
Расчет по формуле CV = (SD / Среднее) * 100 помогает разобраться в данных:
| Обычный тест | Случайные ответы | |
| Среднее значение | 59,9 | 44,8 |
| SD | 10,2 | 12.7 |
| CV | 17,03 | 28,35 |
Глядя на стандартные отклонения 10,2 и 12,7, можно подумать, что тесты дают схожие результаты. Однако, если вы сделаете поправку на разницу средних значений, результаты будут иметь большее значение:
Обычный тест: CV = 17,03
Рандомизированные ответы: CV = 28,35
Коэффициент вариации также можно использовать для сравнения изменчивости между различными показателями. Например, вы можете сравнить показатели IQ с результатами тестов когнитивных способностей Вудкока-Джонсона III.
Примечание: Коэффициент вариации следует использовать только для сравнения положительных данных на шкале отношений. CV имеет мало значения или не имеет никакого значения для измерений на интервальной шкале. Примеры интервальных шкал включают температуры в градусах Цельсия или Фаренгейта, а шкала Кельвина — это шкала отношений, которая начинается с нуля и по определению не может принимать отрицательное значение (0 градусов Кельвина — это отсутствие тепла).
CV имеет мало значения или не имеет никакого значения для измерений на интервальной шкале. Примеры интервальных шкал включают температуры в градусах Цельсия или Фаренгейта, а шкала Кельвина — это шкала отношений, которая начинается с нуля и по определению не может принимать отрицательное значение (0 градусов Кельвина — это отсутствие тепла).
Нужна помощь с конкретным домашним заданием? Посетите нашу страницу обучения!
Посмотрите видео или прочтите статью ниже:
Используйте следующую формулу, чтобы вручную рассчитать CV для генеральной совокупности или выборки.
σ — стандартное отклонение для генеральной совокупности, которое совпадает со значением «s» для выборки.
μ — это среднее значение для генеральной совокупности, которое совпадает с XBar в выборке.
Другими словами, чтобы найти коэффициент вариации, разделите стандартное отклонение на среднее значение и умножьте на 100.
Как найти коэффициент вариации в Excel.
Вы можете рассчитать коэффициент вариации в Excel, используя формулы для стандартного отклонения и среднего.Для данного столбца данных (например, A1: A10) вы можете ввести: «= stdev (A1: A10) / average (A1: A10)), а затем умножить на 100.
Как найти коэффициент вариации вручную: шаги.
Пример вопроса : Студентам дается две версии теста. Один тест имеет заранее заданные ответы, а второй тест имеет рандомизированные ответы. Найдите коэффициент вариации.
| Обычный тест | Случайные ответы | |
| Среднее значение | 50.1 | 45,8 |
| SD | 11,2 | 12,9 |
Шаг 1: Разделите стандартное отклонение на среднее значение для первого образца:
11,2 / 50,1 = 0,22355
Шаг 2: Умножить Шаг 1 на 100 :
0,22355 * 100 = 22,355%
Шаг 3: Разделите стандартное отклонение на среднее значение для второй выборки:
12,9 / 45,8 = 0,28166
Шаг 4: Умножьте шаг 3 на 100 :
0. 28166 * 100 = 28,266%
28166 * 100 = 28,266%
Вот и все! Теперь вы можете сравнить два результата напрямую.
Посетите наш канал YouTube для получения дополнительной информации и советов по статистике.
————————————————— —————————-Нужна помощь с домашним заданием или контрольным вопросом? С Chegg Study вы можете получить пошаговые ответы на свои вопросы от эксперта в данной области. Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Пожалуйста, оставьте комментарий на нашей странице в Facebook .
Биномиальный коэффициент — Статистика Как к
Определения статистики>
Биномиальные коэффициенты говорят нам, сколько способов выбрать k вещей из большего набора . Более формально они определяются как коэффициенты для каждого члена в (1 + x) n . Записывается как, (читать n выбрать k), где — биномиальный коэффициент члена полинома x k .
Записывается как, (читать n выбрать k), где — биномиальный коэффициент члена полинома x k .
Альтернативное обозначение: n C k .
Для неотрицательных целочисленных значений n (число в наборе) и k (количество элементов по вашему выбору) каждый биномиальный коэффициент n C k задается формулой:
Знак «!» символ — факториал.
Примеры
Представьте, что у вас есть 5 элементов {a, b, c, d, f}. Чтобы узнать, сколько различных подмножеств из 2 элементов у него есть, посмотрите на биномиальный коэффициент 5 C 2 .
Это равно 10.
Для более подробного объяснения того, как решить такую формулу, посмотрите следующее видео:
Для более конкретного примера предположим, что президент студенческого клуба должен выбрать трех членов консультативного совета из числа преподавателей. из 24.Чтобы узнать, сколькими способами он мог сделать этот выбор, посмотрите на биномиальный коэффициент 24 C 3 , 24! / (3! 21!) = 2024. Итак, президент студенческого клуба имеет 2024 выбора кабинета.
из 24.Чтобы узнать, сколькими способами он мог сделать этот выбор, посмотрите на биномиальный коэффициент 24 C 3 , 24! / (3! 21!) = 2024. Итак, президент студенческого клуба имеет 2024 выбора кабинета.
Важность биномиального коэффициента в статистике
Биномиальный коэффициент — это гораздо больше, чем простая формула для расчета, сколькими способами вы можете извлечь консультативный совет из пула кандидатов, 4-значную булавку из 10-значного набора или тарелку яблок из корзины такой же.Это также часть описания биномиального распределения, простого распределения вероятностей для часто встречающихся ситуаций с двумя исходами.
Если ваши наблюдения независимы, каждое из них представляет один из двух результатов (подумайте: успех и неудача), ваше количество испытаний фиксировано и вероятность успеха одинакова для каждого испытания, тогда вероятность того, что у вас будет ровно r успехов в течение n независимые испытания будут
Эта формула представляет биномиальное распределение. Здесь p — вероятность успеха в каждом случае, а q = 1-p — вероятность неудачи.
Здесь p — вероятность успеха в каждом случае, а q = 1-p — вероятность неудачи.
Биномиальный коэффициент n select r говорит вам, сколько последовательностей успеха-неудачи из набора всех возможных последовательностей приведут к ровно r успехам. Вероятность возникновения каждой из этих отдельных последовательностей равна p r q n-r .
Список литературы
Биномиальные коэффициенты @ Дартмут. Получено 27 сентября 2017 г. из: https: //math.dartmouth.edu / archive / m19w03 / public_html / Section1-3.pdf
CS4205 Биномиальные коэффициенты. Получено 27 сентября 2017 г. с сайта: http://www.cs.columbia.edu/~cs4205/files/CM4.pdf
. ————————————————— —————————-
Нужна помощь с домашним заданием или контрольным вопросом? С Chegg Study вы можете получить пошаговые ответы на свои вопросы от эксперта в данной области. Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Пожалуйста, оставьте комментарий на нашей странице в Facebook .
Использование коэффициента вариации (COV)
Коэффициент вариации (COV) — это мера относительной дисперсии событий, которая равна отношению между стандартным отклонением и средним значением. Хотя он чаще всего используется для сравнения относительного риска, COV может применяться к любому типу количественного правдоподобия или распределения вероятностей. И в другом математическом контексте COV рассчитывается как отношение между среднеквадратичной ошибкой и средним значением отдельной зависимой переменной.Хотя этот тип анализа COV используется реже, он может иметь большое значение для определения того, подходит ли модель для конкретной задачи.
Ключевые выводы
- В статистическом анализе коэффициент вариации (COV) измеряет относительную дисперсию событий.
- COV равен отношению между стандартным отклонением и средним значением. Хотя COV чаще всего используется для сравнения относительного риска, его можно применять ко многим типам распределения вероятностей.
- COV нецелесообразен, если в выборке сильно присутствуют как положительные, так и отрицательные значения.
- Показатель COV лучше всего использовать, когда почти все точки данных имеют один и тот же знак плюс-минус.
Применение коэффициента вариации
При использовании для оценки инвестиционного риска COV можно интерпретировать аналогично стандартному отклонению в современной теории портфелей (MPT). Но COV, возможно, является лучшим общим индикатором относительного риска, когда он используется для сравнения различных ценных бумаг.Например, предположим, что две разные акции предлагают разную доходность, каждая из которых демонстрирует разное стандартное отклонение. В частности, предположим, что акция A имеет ожидаемую доходность 15% со стандартным отклонением 10%, а акция B имеет ожидаемую доходность 10% в сочетании со стандартным отклонением 5%. В этом сценарии COV для Акции A составляет 0,67 (10% / 15%), а COV для Акции B составляет 0,5 (5% / 10%). Проще говоря: данные свидетельствуют о том, что акции B являются более выгодным вложением с точки зрения риска.
Проще говоря: данные свидетельствуют о том, что акции B являются более выгодным вложением с точки зрения риска.
Преимущества коэффициента вариации
Основным преимуществом COV является его применимость к любым данным поддающимся количественной оценке данным, что открывает путь для сравнительного анализа между двумя несвязанными объектами.Это качество отделяет COV от анализа стандартного отклонения, который не может облегчить значимое сравнение двух независимых переменных.
В качестве меры риска COV измеряет волатильность цен на акции и другие ценные бумаги, позволяя аналитикам сравнивать риски, связанные с различными потенциальными инвестициями. Это помогает финансовым консультантам создавать диверсифицированные портфели, чтобы снизить риск того, что одна инвестиция обернется для чистой стоимости клиента.
Несколько других терминов являются синонимами COV, включая коэффициент вариации, единичный риск и относительное стандартное отклонение.
Нулевой недостаток
Предположим, что среднее значение выборочной совокупности равно нулю. Другими словами, суммы всех значений выше и ниже нуля равны друг другу. В этом случае формула COV бесполезна, потому что она фактически поместит ноль в знаменатель. Следовательно, любое сильное присутствие как положительных, так и отрицательных значений в выборке становится проблематичным для анализа COV. И наоборот, показатель COV процветает, когда почти все точки данных имеют один и тот же знак плюс-минус.
Понимание ваших данных: разница между корреляцией и условной вероятностью
В ноябре я представил некоторую базовую статистику, чтобы помочь стартапам разобраться в своих данных. Затем в прошлом месяце я описал пирамиду вовлеченности, которая упорядочивает поведение пользователя в виде иерархии. Это поможет вам определить самый высокий уровень вовлеченности пользователей, чтобы вы могли выделить ресурсы для достижения этого результата.
В этой записи блога я решил объединить эти концепции и проиллюстрировать, как они работают вместе, на вымышленном примере. В частности, я собираюсь сосредоточиться на корреляции, а затем представить условную вероятность в качестве следующего шага не только к пониманию ваших данных, но и к выработке практических идей.
В частности, я собираюсь сосредоточиться на корреляции, а затем представить условную вероятность в качестве следующего шага не только к пониманию ваших данных, но и к выработке практических идей.
Простой пример корреляции
Предположим, мы создаем социальное приложение с возможностями «добавлять» / «ставить лайки» и «публиковать» (текст, фотографии и т. Д.). Мы предполагаем, что добавление в избранное вызывает меньшее трение пользователей, чем публикация, и хотим выяснить статистическую взаимосвязь между этими двумя действиями.Мы собрали следующие данные:
Если мы построим график данных и применим простую линейную регрессию, мы узнаем, что уклон м составляет 0,417, а значение R 2 равно 0,895 (см. Ниже и всегда не забывайте визуализировать свои данные: квартет Анскомба предоставит вам контекст в виде почему).
Из этих данных мы также можем вычислить коэффициент корреляции Пирсона p , который составляет 0,946. Если вам нужно освежить память из ноябрьской публикации, p показывает линейную связь между двумя наборами данных (т.е. могут ли данные быть представлены линией?).
Если вам нужно освежить память из ноябрьской публикации, p показывает линейную связь между двумя наборами данных (т.е. могут ли данные быть представлены линией?).
И m , и p информируют нас о силе линейной связи между избранным и постами. Однако они также предоставляют четкую информацию:
- Предполагая простую линейную регрессию, наклон можно интерпретировать как оценочное значение изменения в Y (посты), соответствующее одному изменению единицы X (избранное). Сила этой связи составляет R 2 (чем ближе к 1, тем лучше соответствие).
- Коэффициент корреляции находится в диапазоне от -1 до 1. Чем ближе значение к 1, тем ближе две переменные к идеальной линейной зависимости.
- Обратите внимание, что для линейной регрессии методом наименьших квадратов с предполагаемым членом пересечения (как в этом примере) R 2 равно p 2 .
Возвращаясь к примеру, кажется, что существует значительная линейная корреляция между добавлением в избранное и публикацией. В частности, корреляция 0.94 означает, что 89,5% (из 0,94 2 ) вариативности публикации можно описать как добавление в избранное (и наоборот).
В частности, корреляция 0.94 означает, что 89,5% (из 0,94 2 ) вариативности публикации можно описать как добавление в избранное (и наоборот).
Однако недостатком корреляции является то, что она не подразумевает причинно-следственную связь. Поскольку мы до сих пор не знаем, поддается ли добавление в избранное публикации, нам нужно подумать об условной вероятности.
Вероятность 101
Вероятность — это мера вероятности того, что событие произойдет, и находится в диапазоне от 0 (невозможность) до 1 (достоверность).Как правило, вероятности можно описать как статистическое количество исходов, считающихся благоприятными, деленное на количество всех исходов. Некоторые основные понятия:
Вероятность события A записывается как P (A).
Противоположность или дополнение события A — это P (?).
например Если A — это событие вытягивания сердца из колоды карт, то P (A) = 13/52 = 1/4. Таким образом, вероятность не выбрать сердце P (?) = 1 — 1/4 = 3/4.
Если два события, A и B, независимы, то их совместная вероятность (т.е. пересечение) равно P (A? B) = P (A) P (B).
например Если две монеты подбрасываются одновременно, вероятность того, что обе монеты выпадут орлом, равна P (A? B) = 1/2 * 1/2 = 1/4.
Если событие A или B происходит в единственном экземпляре, это объединение обозначается как P (A? B).
Если эти события являются взаимоисключающими, то вероятность любого из них равна P (A? B) = P (A) + P (B).
например Шанс вытащить сердце (A) или лопату (B) из колоды карт равен P (A? B) = 1/4 + 1/4 = 1/2.
Если события не исключают друг друга, то P (A? B) = P (A) + P (B) — P (A? B).
например Вероятность вытянуть сердечко (A), лицевую карту (B) или одну из них равна P (A? B) = 13/52 + 12/52 — 3/52 = 11/26.
Условная вероятность
Вероятность некоторого события A с учетом наступления некоторого другого события B определяется как P (A | B) = P (A? B) / P (B) = P (B | A) P (A) / P ( Б).
например Допустим, у нас есть сумка с 10 блоками: 5 красных и 5 синих. Вероятность выбора красного в первом розыгрыше составляет 5/10 или 1/2, но после взятия второго блока вероятность того, что он будет красным или синим, зависит от того, что было выбрано ранее.Если был взят красный блок, то вероятность снова выбрать красный блок была бы 4/9.
Понимание концепции условной вероятности имеет решающее значение, поскольку она лежит в основе теоремы Байеса и многих алгоритмов машинного обучения.
Пример условной вероятности
Возвращаясь к нашему набору данных, приведенному выше, мы можем вычислить вероятность того, что пользователь отправит сообщение, учитывая, что он / она поставили в избранное. Однако для этого нам нужны более подробные данные; то есть вместо того, чтобы смотреть на общее количество избранных и сообщений для каждого пользователя, мы должны рассматривать каждое избранное, сообщение или избранное сообщение и как отдельное событие (независимо от пользователя).
Например, рассмотрим пользователя 9, у которого всего 9 избранных и 3 сообщения за (скажем) 100 посещений. Его профиль активности может выглядеть так:
Отсюда вычисляем:
P (Любимый) = 9/100 = 0,09
P (Пост) = 3/100 = 0,03
P (Избранное? Опубликовать) = 2/100 = 0,02
Следовательно, условная вероятность того, что этот пользователь разместит что-то, учитывая, что он / она что-то одобрил, составляет примерно 22%:
P (Сообщение | Избранное) = P (Избранное? Сообщение) / P (Избранное) = 0.02 / 0,09 = 0,22
Чтобы определить общую вероятность публикации пользователем сообщения с учетом того, что он / она опубликовал, вы должны подсчитать все действия для всех посещений всех пользователей. Не просто складывайте вероятности каждого пользователя.
Наконец, предположим, что мы расширили этот пример, чтобы вычислить общую условную вероятность, и нашли, что она равна 0,75. Поскольку это сильная сторона, вы можете сосредоточить свои усилия на том, чтобы побудить пользователей добавить в избранное, поскольку вы знаете, что высока вероятность того, что они также будут публиковать сообщения. Вы даже можете воспользоваться пирамидой вовлеченности и вычислить вероятность того, что кто-то окажется в фаворите при другом более низком барьере для входа (т.е. авторизоваться). И наоборот, если вероятность низкая, вы можете сосредоточиться на другом занятии.
Вы даже можете воспользоваться пирамидой вовлеченности и вычислить вероятность того, что кто-то окажется в фаворите при другом более низком барьере для входа (т.е. авторизоваться). И наоборот, если вероятность низкая, вы можете сосредоточиться на другом занятии.
Закрытие
Важно понимать взаимосвязь между двумя переменными (корреляцией и зависимостью), но для получения более действенных результатов вы можете рассмотреть возможность вычисления вероятностей (правдоподобия).
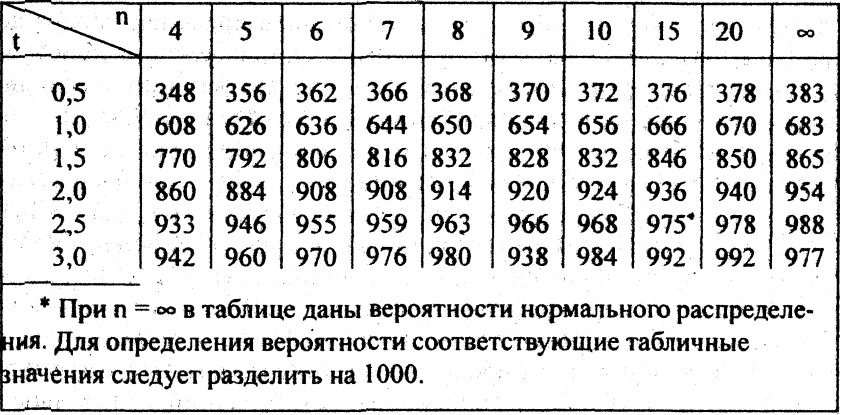
| 1.
Исследовательский анализ данных 1,3. Методы EDA 1.3.3. Графические методы: алфавитный
| |||
| Цель: Графический метод определения параметров формы Распределительное семейство, которое наилучшим образом соответствует набору данных | График коэффициента корреляции графика вероятности (PPCC)
(Филлибен, 1975)
это графический метод определения
параметр формы для
семейство распределения, которое лучше всего описывает набор данных. Этот метод подходит для семей, например
Weibull, которые определяются одним параметром формы
и параметры местоположения и масштаба,
и не подходит для таких дистрибутивов, как
нормальные, которые определяются только местоположением и масштабом
параметры. Этот метод подходит для семей, например
Weibull, которые определяются одним параметром формы
и параметры местоположения и масштаба,
и не подходит для таких дистрибутивов, как
нормальные, которые определяются только местоположением и масштабом
параметры.График PPCC создается следующим образом. Для серии значений для параметра формы коэффициент корреляции равен вычислено для вероятности график, связанный с заданным значением параметра формы.Эти коэффициенты корреляции отложены против их соответствующие параметры формы. Максимальный коэффициент корреляции соответствует оптимальному значение параметра формы. Для большей точности два могут быть сгенерированы итерации графика PPCC; первый для найти правильный район, а второй — в порядке настройка сметы. График PPCC используется в первую очередь, чтобы найти хорошее значение
параметр формы. В
Затем создается график вероятности
найти оценки параметров местоположения и масштаба и в
дополнительно предоставить графическую оценку адекватности
распределение соответствия. | ||
| Сравнить распределения | Помимо поиска хорошего выбора для оценки формы
параметр данного распределения, график PPCC может быть полезен
в решении, какая распределительная семья наиболее
подходящее. Например, учитывая набор данных о надежности,
вы можете сгенерировать графики PPCC для логнормального, логнормального,
гамма и обратные гауссовские распределения и, возможно, другие,
на одном
страница.На этой странице будет показано лучшее соотношение цены и качества
параметр формы для нескольких распределений и будет
дополнительно укажите, какие из этих распределительных
семей обеспечивает наилучшее соответствие (по оценке
коэффициент корреляции графика максимальной вероятности). Это
есть, если максимальное значение PPCC для Weibull составляет 0,99 и
только 0,94 для логнормального значения, тогда мы могли бы разумно
сделать вывод, что семья Вейбулла — лучший выбор. | ||
| График Тьюки-Лямбда PPCC для симметричных распределений | График Tukey Lambda PPCC с формой
параметр λ , особенно полезен для симметричных
раздачи.Он указывает, является ли распределение коротким или длинным.
хвостатые, и это может дополнительно указывать на несколько общих распределений.
В частности,
 Если максимальное значение близко к -1, это подразумевает выбор
очень длиннохвостое распределение, такое как Коши. Если
максимальное значение больше 0,14, это означает
короткохвостое распределение, такое как бета или равномерное. Если максимальное значение близко к -1, это подразумевает выбор
очень длиннохвостое распределение, такое как Коши. Если
максимальное значение больше 0,14, это означает
короткохвостое распределение, такое как бета или равномерное.График Tukey-Lambda PPCC используется для предположения соответствующее распределение.Вам следует продолжить с PPCC и вероятностные графики соответствующих альтернатив. | ||
| Используйте суждение при выборе подходящего дистрибьютора Семья | Сравнивая модели распределения, не выбирайте просто
тот, у которого максимальное значение PPCC. Во многих случаях несколько
распределительные соответствия обеспечивают сопоставимые значения PPCC. Для
Например, логнормальный и Вейбулл могут соответствовать заданному набору
данных о надежности достаточно хорошо.Обычно мы бы
учитывать сложность раздачи. Это
более простое распределение с немного меньшим значением PPCC
может быть предпочтительнее более сложного распределения. Точно так же
может быть теоретическое обоснование с точки зрения
лежащая в основе научная модель для предпочтения распределения
с несколько меньшим значением PPCC в некоторых случаях.
В других случаях нам может не понадобиться знать,
модель оптимальна, только адекватна нашим целям.То есть мы можем использовать методы, разработанные для
нормально распределенные данные, даже если подходят другие распределения
данные несколько лучше. Это
более простое распределение с немного меньшим значением PPCC
может быть предпочтительнее более сложного распределения. Точно так же
может быть теоретическое обоснование с точки зрения
лежащая в основе научная модель для предпочтения распределения
с несколько меньшим значением PPCC в некоторых случаях.
В других случаях нам может не понадобиться знать,
модель оптимальна, только адекватна нашим целям.То есть мы можем использовать методы, разработанные для
нормально распределенные данные, даже если подходят другие распределения
данные несколько лучше. | ||
| Образец участка | Ниже приведен график PPCC.
100 нормальных случайных чисел.
Максимальное значение коэффициента корреляции = 0,997.
при λ = 0,099. Этот график PPCC показывает, что:
| ||
| определение: | График PPCC состоит из:
| ||
| Вопросы | График PPCC отвечает на следующие вопросы:
| ||
| Важность | Многие статистические анализы основаны на предположениях о распределении
о населении, от которого были получены данные. Однако распределительные семьи могут иметь
кардинально разные формы в зависимости от стоимости формы
параметр. Следовательно, найдя разумный выбор формы
параметр — необходимый шаг в анализе. Во многих анализах
поиск хорошей модели распределения для данных является основным
фокус анализа. В обоих случаях график PPCC
ценный инструмент. Однако распределительные семьи могут иметь
кардинально разные формы в зависимости от стоимости формы
параметр. Следовательно, найдя разумный выбор формы
параметр — необходимый шаг в анализе. Во многих анализах
поиск хорошей модели распределения для данных является основным
фокус анализа. В обоих случаях график PPCC
ценный инструмент. | ||
| Связанные методы | График вероятности Оценка максимального правдоподобия Оценка методом наименьших квадратов Метод оценки моментов | ||
| Программного обеспечения | Графики PPCC в настоящее время недоступны для наиболее распространенного общего назначения.
статистические программы.Однако основная техника
основан на вероятностных графиках и коэффициентах корреляции, поэтому
должна быть возможность писать макросы для графиков PPCC в статистических
программы, поддерживающие эти возможности. Dataplot поддерживает графики PPCC. Dataplot поддерживает графики PPCC. | ||
статистика — От коэффициента корреляции к условной вероятности
В первом приближении:
Мы исследуем пару фирм и выбираем одну наугад. Пусть $ A $ будет событием, когда фирма станет более успешной, а $ B $ — событием, что у фирмы более сильный генеральный директор.Мы ищем $ \ mathsf P (A \ mid B) $, вероятность того, что фирма будет более успешной при условии, что у нее более сильный генеральный директор.
Измерение корреляции по определению: $$ \ begin {align} \ rho ~ = ~ & \ dfrac {\ mathsf P (A \ cap B) ~ — ~ \ mathsf P (A) ~ \ mathsf P (B) } {\ sqrt {~ \ mathsf P (A) ~ (1- \ mathsf P (A)) ~ \ mathsf P (B) ~ (1- \ mathsf P (B)) ~}} \\ [2ex] ~ = ~ & \ dfrac {(\ mathsf P (A \ mid B) -1) ~ \ mathsf P (B)} {\ sqrt {~ \ mathsf P (A) ~ (1- \ mathsf P (A)) ~ \ mathsf P (B) ~ (1- \ mathsf P (B)) ~}} \ end {align} $$
Итак, половина каждой пары будет иметь более сильного генерального директора, а половина каждой пары будет более успешной; просто не обязательно одна и та же половина. Итак, $ \ mathsf P (A) = \ tfrac 12, \ mathsf P (B) = \ tfrac 12 $ и, следовательно:
Итак, $ \ mathsf P (A) = \ tfrac 12, \ mathsf P (B) = \ tfrac 12 $ и, следовательно:
$$ \ begin {align} \ rho ~ = ~ & 2 ~ \ mathsf P (A \ mid B) -1 \\ [2ex] \ mathsf P (A \ mid B) ~ = ~ & \ dfrac {1+ \ rho} {2} \\ [1ex] ~ = ~ & \ dfrac {1 + 0.30} {2} \\ [1ex] ~ = ~ & 0.65 \ end {align} $$
Более разумно:
Мы, , могли бы рассматривать успешность и силу генерального директора любой компании $ i $ как совокупность двумерных нормальных случайных величин ($ A_i, B_i $) с идентичными, хотя и зависимыми распределениями.2 \\ & = \ mathsf P (A) (1- \ mathsf P (A)) \\ [2ex] \ mathsf {Cov} (\ mathbf 1_A, \ mathbf 1_B) & = \ mathsf E (\ mathbf 1_A \ mathbf 1_B) — \ mathsf E (\ mathbf 1_A) \ mathsf E (\ mathbf 1_B) \\ & = \ mathsf E (\ mathbf 1_ {A \ cap B}) — \ mathsf E (\ mathbf 1_A) \ mathsf E (\ mathbf 1_B) \\ & = \ mathsf P (A \ cap B) — \ mathsf P (A) \ mathsf P (B) \ end {split} $$
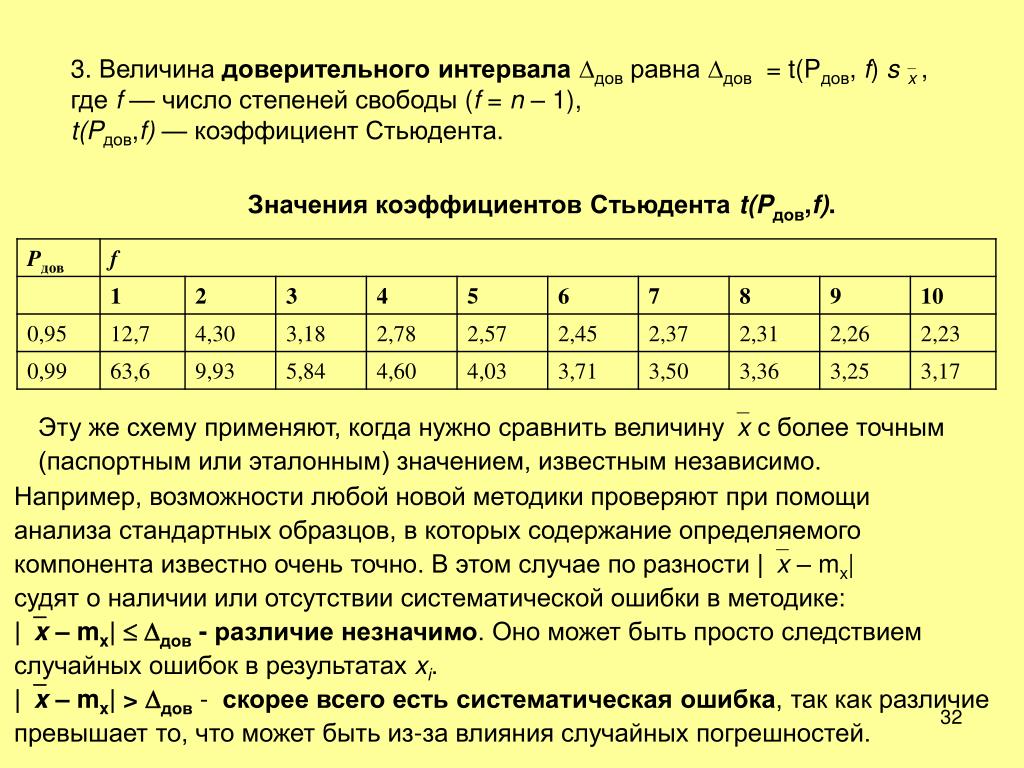
Коэффициенти значения вероятности среднего и дисперсионного уравнения
Контекст 1
. .. применение теста единичного корня ADF для пяти серий показывает, что каждая из эталонных серий имеет единичный корень.Таблица 2 суммирует значения, обозначающие коэффициенты и вероятностные значения уравнений среднего и дисперсии всех рядов моделей, выбранных выше. Столбец «Итого» таблицы 2 показывает, что CNX Nifty имеет максимальную волатильность в ряду, за которым следуют доллар, CNX_500, фунт и евро. …
.. применение теста единичного корня ADF для пяти серий показывает, что каждая из эталонных серий имеет единичный корень.Таблица 2 суммирует значения, обозначающие коэффициенты и вероятностные значения уравнений среднего и дисперсии всех рядов моделей, выбранных выше. Столбец «Итого» таблицы 2 показывает, что CNX Nifty имеет максимальную волатильность в ряду, за которым следуют доллар, CNX_500, фунт и евро. …
Контекст 2
… 2 суммирует значения, обозначающие коэффициенты и вероятностные значения средних и дисперсионных уравнений всех рядов моделей, выбранных выше.Столбец «Итого» таблицы 2 показывает, что CNX Nifty имеет максимальную волатильность в ряду, за которым следуют доллар, CNX_500, фунт и евро. Это также показывает, что серия евро имеет наименьшую волатильность, но изученная волатильность, измеренная GARCH (-1), является максимальной для серии евро, за которой следуют фунт, CNX Nifty, CNX_500 и доллар. …
Контекст 3
.